Elasticsearch
Quick Summary
Elasticsearch is a distributed search engine that serves as a high-performance vector database for your RAG application. It was designed for scalability, high-speed queries, relevance optimization, and efficiently handles production-scale retrieval workloads. Learn more about Elasticsearch here.
To get started, install the Python library through the CLI using the following command:
pip install elasticsearch
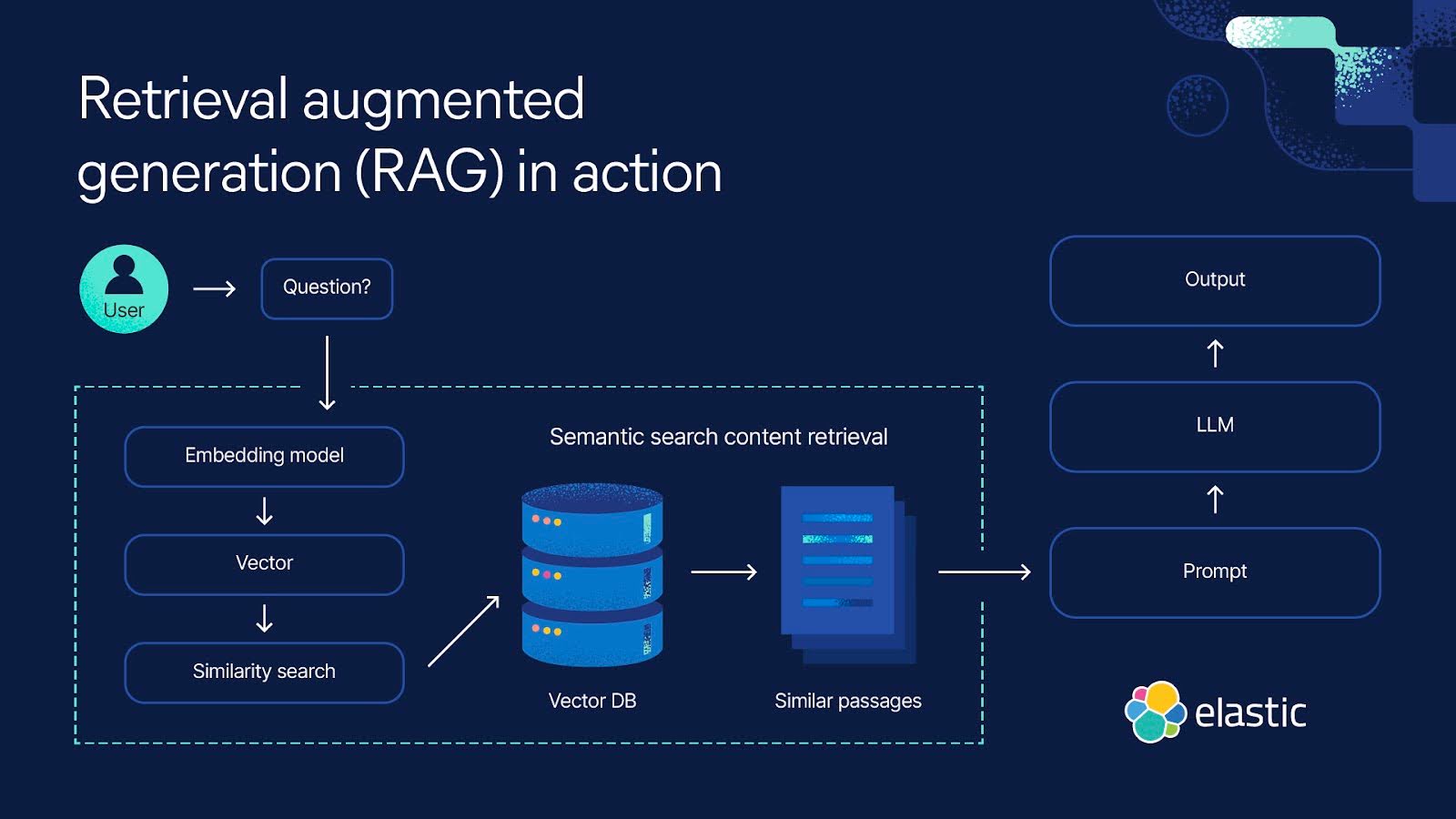
DeepEval allows you to evaluate your Elasticsearch retriever and optimize retrieval hyperparameters such as top-K, embedding model, and/or similarity function. This diagram provides a great overview of how Elasticsearch functions as a vector database within your RAG pipeline:
Setup Elasticsearch
To get started, simply connect to your local Elastic cluster using the "elastic" username and the password set in your environment variable ELASTIC_PASSWORD.
import os
from elasticsearch import Elasticsearch
username = 'elastic'
password = os.getenv('ELASTIC_PASSWORD') # Value you set in the environment variable
client = Elasticsearch(
"http://localhost:9200",
basic_auth=(username, password)
)
Next, create an Elasticsearch index with the correct type mappings to store text and embedding as a dense_vector for similarity search, ensuring efficient retrieval.
# Create index if it doesn't exist
if not es.indices.exists(index=index_name):
es.indices.create(index=index_name, body={
"mappings": {
"properties": {
"text": {"type": "text"}, # Stores chunk text
"embedding": {"type": "dense_vector", "dims": 384} # Stores embeddings
}
}
})
Finally, define an embedding model to embed your document chunks before adding them to your Elasticsearch index for retrieval.
# Load an embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Example document chunks
document_chunks = [
"Elasticsearch is a distributed search engine.",
"RAG improves AI-generated responses with retrieved context.",
"Vector search enables high-precision semantic retrieval.",
...
]
# Store chunks with embeddings
for i, chunk in enumerate(document_chunks):
embedding = model.encode(chunk).tolist() # Convert text to vector
es.index(index=index_name, id=i, body={"text": chunk, "embedding": embedding})
Evaluating Elasticsearch Retrieval
To begin evaluating your Elasticsearch retriever, simply prepare an input query, generate a response to the input using your RAG pipeline, and store the input, actual_output, and retrieval_context values in an LLMTestCase for evaluation.
An LLMTestCase allows you to create unit tests for your LLM applications, helping you identify specific weaknesses in your RAG application.
First, retrieve the retrieval_context from your Elasticsearch index for your input query.
def search(query):
query_embedding = model.encode(query).tolist()
res = es.search(index=index_name, body={
"knn": {
"field": "embedding",
"query_vector": query_embedding,
"k": 3 # Retrieve the top match
"num_candidates": 10 # Controls search speed vs accuracy
}
})
return res["hits"]["hits"][0]["_source"]["text"] if res["hits"]["hits"] else None
query = "How does Elasticsearch work?"
retrieval_context = search(query)
Next, pass the retrieval context to your LLM to generate a response.
prompt = """
Answer the user question based on the supporting context
User Question:
{input}
Supporting Context:
{retrieval_context}
"""
actual_output = generate(prompt) # hypothetical function, replace with your own LLM
Finally, run evaluate() using deepeval to assess contextual recall, precision, and relevancy of your Elasticsearch retriever.
These 3 contextual metrics help evaluate the performance of your retriever. For more details on retriever evaluation, check out this guide.
from deepeval.metrics import (
ContextualRecallMetric,
ContextualPrecisionMetric,
ContextualRelevancyMetric,
)
from deepeval.test_case import LLMTestCase
from deepeval import evaluate
...
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
retrieval_context=retrieval_context,
expected_output="Elasticserach uses inverted indexes for keyword searches and dense vector similarity for semantic search.",
)
evaluate(
[test_case],
metrics=[
ContextualRecallMetric(),
ContextualPrecisionMetric(),
ContextualRelevancyMetric(),
],
)
Improving Elasticsearch Retrieval
To improve your Elasticsearch retriever, experiment with various hyperparameters and prepare LLMTestCases using generations from different versions of these retrievers. Analyzing improvements and regressions in contextual metric scores (the 3 metrics we defined above) will help you determine the optimal hyperparameter combination for your Elasticsearch retriever.
For a more detailed guide on iterating on your retriever's hyperparameters, you may want to check out this guide.